


The anatomy of an active metadata platform, bringing data analysts to the table, mapping data journey with column lineage, and more
✨ Spotlight: The Anatomy of an Active Metadata Platform

Welcome to this week's edition of the ✨ Metadata Weekly ✨ newsletter.
Every week I bring you my recommended reads, curated jobs in the modern data stack, and share my (meta?) thoughts on everything around metadata.
If you find this edition interesting, please do share it with your friends and colleagues who may like reading it too. Hope you enjoy these reads below.
✨ Spotlight: The Anatomy of an Active Metadata Platform
When we started working on Atlan, categories like "Active Metadata" didn't even exist. We knew it was important but struggled to explain it to people.
This year, we witnessed an incredible moment for #metadata in the modern data stack! Gartner took a huge step by scrapping its Magic Quadrant for Metadata Management Solutions and replacing it with a Market Guide for Active Metadata.
With Gartner's introduction to Active Metadata as a new category for the future, the modern data stack took a transformational leap in how it approached metadata. It will become the force behind augmented data catalogs, autonomous DataOps, data fabric and data mesh, data and analytics governance, and consumerization of data tools.
I believe the active metadata platform of the future will be built on a few principles:
One size doesn’t fit all in augmented data management: Every company, industry, and context is different, and a single ML algorithm won’t solve all your data management problems. Data Catalog 3.0 era tools understand this and build programmability and customization into AI/ML algorithms.
Open by default will drive infinite metadata-driven use cases: Metadata will be key to unlocking several futuristic operational use cases in the modern data stack, like auto-tuning pipelines and CI/CD pipelines. For this, the fundamental metastore needs to be open to allow teams to innovate. I'm really bullish about the idea of a metadata lake (a unified repository to store all kinds of metadata, in raw and processed forms, built on open APIs and powered by a knowledge graph) and excited to see this catching on in the industry!
Context should be embedded into teams’ daily workflows: Nobody wants to go to a separate "catalog" to get context about their data assets. Active metadata platforms understand this and ensure that context is available in the tools users use every day — BI tools, Slack, JIRA, and more!
Earlier this year I shared a break down of these key components and explained some real-life use cases of active metadata in a blog. You can check it out here.
P.S. Atlan was named in Gartner's Inaugural Guide for Active Metadata Management. 👑
❤️ Fave Links for This Week
Bring data analyst to the table by Petr Janda
Another great article from Petr! I loved his call to action on the one simple thing that business leaders can do to truly build a data-driven company: “Next time you encounter an important decision that should be based on data, resist the habit of requesting the next data pull. Instead, go to the analyst with a question and an invitation to the decision-making table. Not just in the boardroom: in every room where important decisions get made.”
When we were a data team ourselves, we had a value called "Problem First, Solution Second". This meant that we wouldn't write a line of code until we truly understood the problem to be solved. It was a really hard value to hold ourselves to, and some customers detested us for it. But it allowed us to ensure we were truly creating impact in our work rather than becoming "cogs in the wheel".
To add on to what Petr said, my two cents to business leaders: RESIST THE URGE to tell your data team what to build or what data you need. Instead, start by telling them the problem you want to solve. You'll be surprised by how the quality of your decisions improves.
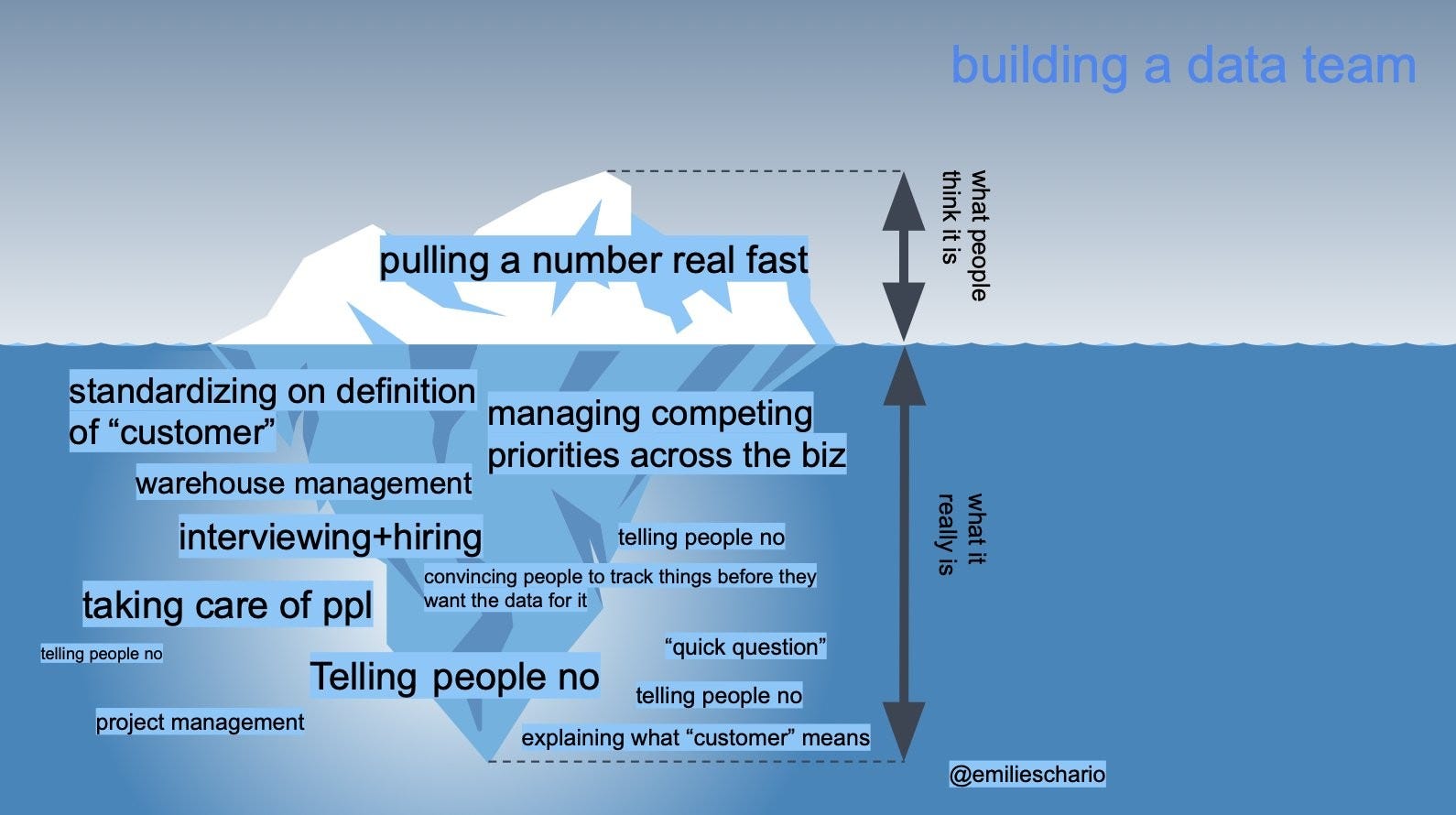
My two cents to data practitioners: Stop measuring yourself on how many "data requests" you service. Remember that our goal as data practitioners is to impact decision-making. I am bullish on the idea of data teams moving from a "service mindset" to a "product mindset" — and thinking of their work outputs as products and their success metrics as when users use their products!
Emilie and Taylor's blog on Locally Optimistic covers this idea really well — Run Your Data Team Like a Product Team.
Lastly, nothing explains it better than this iconic image by Emilie Schario.
Mapping our data journey with column lineage by Borja Vazquez
Finally, a blog where someone calls out the importance of column-level lineage. There's so much buzz in the industry about "lineage" and I've been pretty disappointed by how most vendors in new spaces like observability have been building and creating a ton of marketing buzz around table-level lineage.
Don't get me wrong — table-level lineage is better than not having ANY understanding of your data flows, but in my opinion, the real magic happens when you are able to go down to the column level and map column-to-column relationships. That's when use cases like observability, column-level classifications, and root cause analysis come alive.
Great data teams should aim to understand how data evolves and how it’s being used in order to keep their data assets up to date.
P.S. I love "Data Cartographers", a term coined by Borja and his team.

The brilliant team at Snapcommerce is hiring a Director of Data Analytics & Engineering for building the vision for and executing their data mandate. Reach out to Henry in case you're interested to learn more.
Every week, my partner in crime Surendran curates a list of open roles in data teams doing interesting work.
Christopher and the team at Metro.digital are hiring a Data Engineer (based in Düsseldorf, Germany).
Mark and the team at Funding Societies are looking for a Data Scientist (based in Singapore) and Data Analyst (based in Indonesia).
Huy and the Zwift team are hiring a Director of Data Governance (based in California, US) who will lead Zwift's overall Data Governance Program.
You can check out more interesting jobs featured in the Modern Data Jobs newsletter here.
I'll see you next Tuesday with more interesting stuff around the modern data stack. Meanwhile, you can subscribe to this newsletter and connect with me on LinkedIn here.