
Data Quality ≠ Data Trust: Bridging the Data Trust Gap
The first step to building trust in data is to understand the core problem: the data trust gap.

A broken pipeline. A source system gone down. A change made to a column name.
Three unique root causes, but the same end result: broken trust.
I recently heard three different stories from three data leaders about how trust broke in their organization. The first is from Robert-Clifford Jones, Contentful’s Head of Data Intelligence and Governance. In a blog on Contentful’s journey with Atlan, Robert spoke about every data leader’s nightmare: the 3 a.m. phone call.
“Our models run batch processing through the night and everything failed. It was the end of the month, so we couldn’t do all our closing reports and check all of our financial reporting on Monday, as was expected,” Robert shared. “I got a phone call at three o’clock in the morning going ‘What’s going on? Where’s this problem? Can you fix it?’”
Thankfully, Robert’s team resolved the issue, but the broken pipeline could have broken trust. If the CFO opened the report on Monday morning and saw numbers that didn’t add up, would they trust the report? Would they trust any report they opened that week?
Another data leader, this time from a global supply chain company, echoed the sentiment. She told me how a dashboard, powered by two source systems, failed to show updated numbers because one system went down. Unaware, a business user overbooked a shipping vessel based on the data he saw, only to find out later that there was no room on the vessel.
“So we had to tell our customer, to whom we made a promise, that we’re going to have to push their shipment. And they weren’t thrilled at all,” the data leader said. While the root cause of the problem — a source system going down — was different from Robert’s broken pipelines, the impact was the same: broken trust with the business user and the customer.
The final story comes from a software engineer, who urged his data team to change the name of a column. Before the data team could merge the pull request in GitHub, Atlan’s impact analysis showed up with a list of 1,100 impacted models. The data leader told me, “Everything would basically break. All of our dashboards, our metrics, our reporting tables.”
Once again, we have a different root cause, but the same broken trust. If the column name were changed, hundreds of business users reliant on downstream reports and dashboards would have lost trust in the data team.
From broken pipelines to column name changes, there isn’t just one way to break trust. Trust breaks across tools and teams, with no warning sign. This is today’s reality for data teams, but it’s one that we can fix, if we understand the core problem: the data trust gap.
Introducing the Data Trust Gap ✨
The data trust gap refers to the separation that exists between data producers and data consumers, when there’s no visibility, transparency, and collaboration between them.
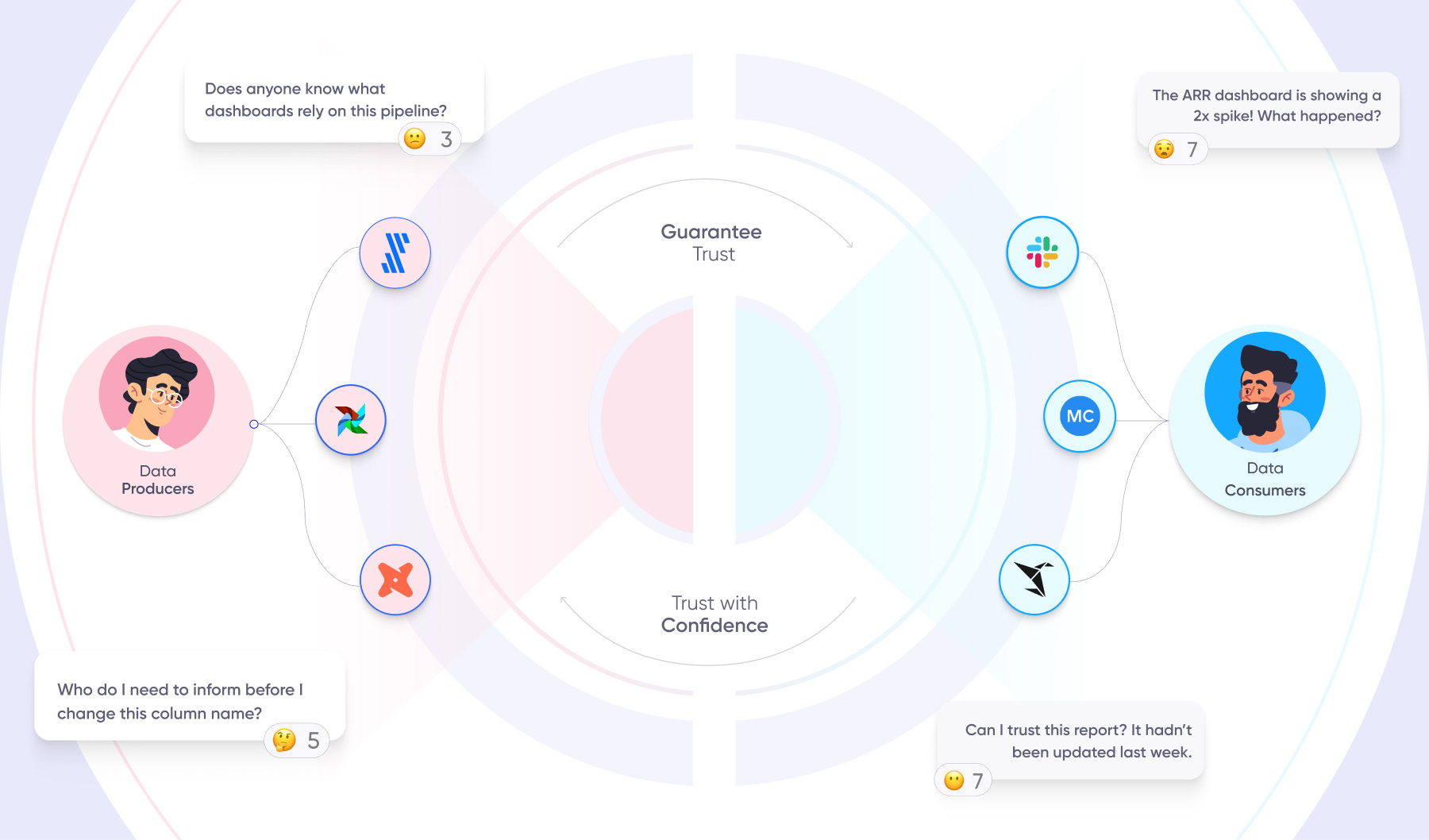
Data producers, like source administrators, data engineers, and analytics engineers, are on the left-hand side of the data pipeline. They live in a multitude of tools, ranging from SaaS applications, like Salesforce, to operational tools, like Airflow, dbt, and Fivetran.
Data consumers, like data analysts and everyday business users, are on the right hand-side of the data pipeline. They analyze and report data in Business Intelligence tools like Sigma and ThoughtSpot.
For data producers, the data consumer world is a black box. When a data producer asks himself, “What downstream dashboards and decisions will this model change impact?”, he doesn’t know how to answer the question without asking every business user how the model is used.
Jorge Vasquez, Datacamp’s Director of Analytics, elucidated this missing visibility for data producers when his team was looking to migrate to a new marketing analytics tool.
“When we were deprecating our web analytics clickstream tool, the way that tool worked is that you embed it in the code of your site, and it collects clickstream data… and it sends that into your data warehouse in real-time,” Jorge explained. “The problem is that, as we wanted to move towards another tool, we needed to understand where all that data from our previous tool was being sent, and it took a lot of time for one analyst to figure out where all that data was going and how it was being consumed.”
To avoid breaking trust, Jorge and his team spent hours trying to navigate the data trust gap. But
For data consumers on the other side of the pipeline, the data producer world is a black box. When a data consumer looks at a dashboard that hasn’t been updated and asks herself, “Why haven’t the numbers been updated?”, she doesn’t know who to reach out to in order to find out.
Lisa Smits, Swapfiets’ Data & Analytics Manager, was looking to solve this exact problem for her data consumers.
“We got a lot of questions from people, like ‘How is that calculated?’ or ‘We see this number in this dashboard, but in this dashboard, it’s completely different. How does that work?’,” Lisa explained. “There was no ownership, no transparency, and no central place for us to write down terms, or explain what metrics meant and how they were calculated. It took a lot of time to answer these ad-hoc things. To lose trust is easy, but to gain that trust back is hard. That’s when we started taking this seriously. We wanted to have a high-quality, trustworthy BI environment.”
What does it take to fulfill Lisa’s dream of having a trustworthy BI environment and save Jorge’s team hours in migrating tools? In other words, what does it take to bridge the data trust gap?
Bridging the Gap in the Modern Data Stack
Data trust isn’t a new problem. Over the last few years, every tool in the modern data stack has invested in building trust, whether for data producers or consumers.
Just last year, Fivetran announced its Metadata API, helping create visibility and trust by surfacing Fivetran connectors in a customer’s data catalog, providing end-to-end lineage all the way to the source. Around the same time, dbt announced its Semantic Layer, in an attempt to bridge the gap between business metrics and the data team. Soda and dbt launched data testing frameworks for data engineers to write data quality tests as a part of their development process. Monte Carlo and Metaplane offer post-facto data observability for data teams. And last but not least, Astronomer and OpenLineage are collaborating to make operational metadata and lineage available for the first time with the rest of the modern data stack.
But with all this investment in building data trust, why have we still not fully bridged the data trust gap? The answer lies in one core insight.
If there isn’t just one way to break trust, there isn’t just one way to build trust either.
Trust is a Team Sport
Bridging the data trust gap is about creating visibility, transparency, and trust between data producers and data consumers. But that can’t happen without the tools we use everyday communicating through metadata.
For data consumers, operational metadata from Airflow, dbt, and Fivetran is essential to understand upstream pipelines that feed their reports and dashboards. If an Airflow job fails, how does a business user in Sigma find out what happened to his dashboard?
For data producers, business metadata from Sigma, ThoughtSpot, and Tableau is critical to understanding downstream usage. If a model has been updated, how does a data engineer know who to communicate that to?
The reality is that trust is a team sport.
To build trust — for data consumers, data producers, and every human of data — the modern data stack needs to come together. We need operational metadata to inform analysts of the status of their reports and dashboards. We need quality metadata to ensure reliability and accuracy. We need business metadata to understand the millions of ways in which data is used. We need metrics definitions to understand what that metric on the dashboard actually means. And we need end-to-end lineage connecting the entire data pipeline together.
The Missing Bridge to the Data Trust Gap: The Metadata Control Plane
What does a bridge between the left and right side of the pipeline look like? The answer could lie in a single metadata control plane that consolidates metadata as trust signals from data producers and activates it into tools that data consumers use everyday. There are 4 critical characteristics of this metadata control plane:
1. A single pane of glass for trust signals

Individual tools in the modern data stack have made significant strides, but the data trust gap can’t be bridged with piecemeal solutions.
The humans of data need one single pane of glass that brings trust metadata from the entire data stack together as consumable trust signals: data quality tests from dbt and Soda, observability alerts from Monte Carlo, and operational, pipeline metadata from Fivetran and Airflow.
2. End-to-end lineage-based automation to activate trust signals

Data producers can’t manually inform every business user when a pipeline fails or a model has been updated, yet data consumers need to stay informed and aware of any upstream changes. The solution? A metadata automation layer that propagates trust signals, such as alerts and notifications, from source to destination. In the right place, at the right time.
3. Embedded trust signals for data consumers in BI and collaboration tools
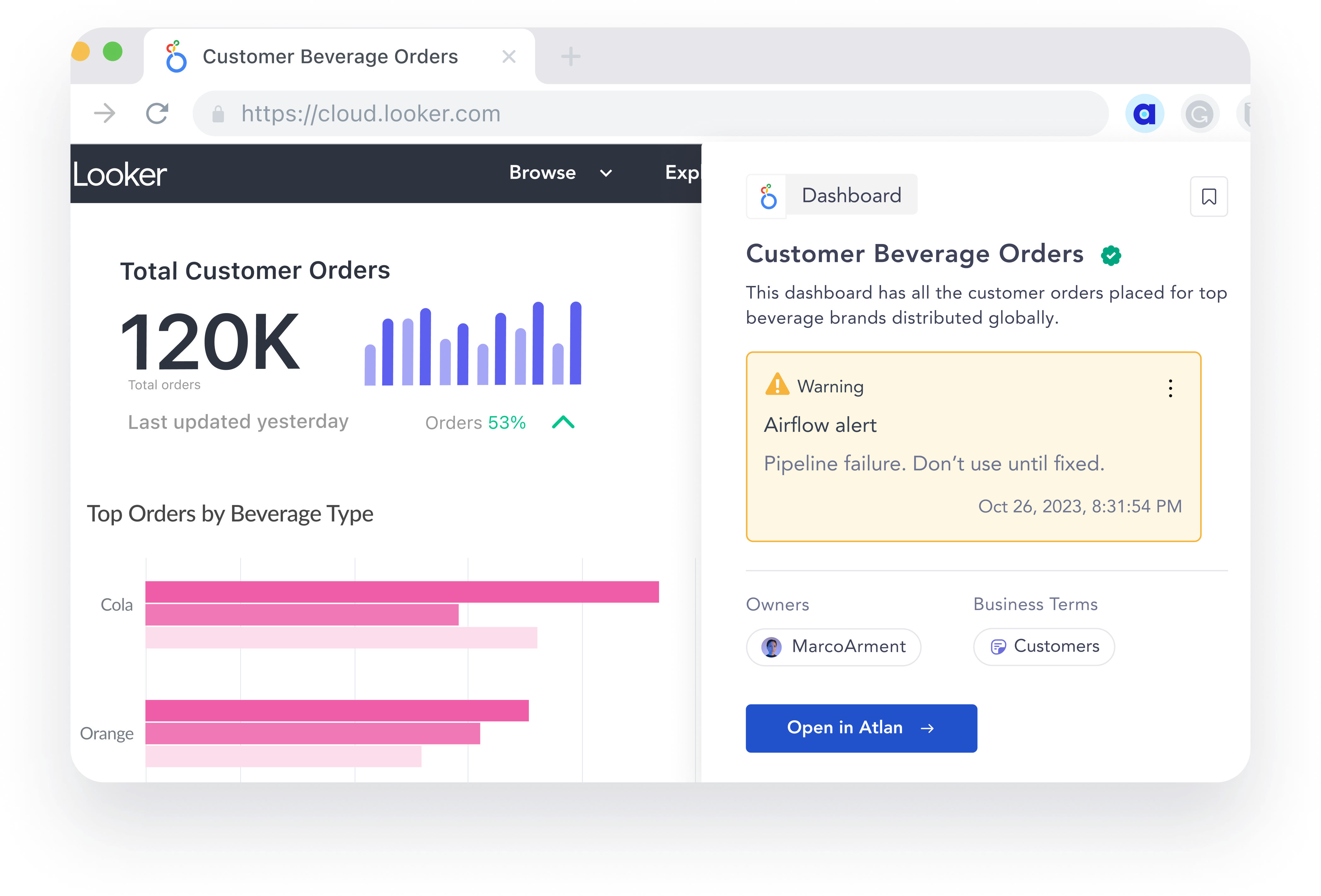
Trust signals are of no use if they live in one singular tool or location. Through integrations with BI tools, such as Tableau and Sigma, and collaboration tools, such as Slack and Microsoft Teams, metadata platforms need to embed trust signals into the daily works of data consumers.
4. Embedded warnings for data producers about the trust impact of their actions

What’s Next?
A broken pipeline. A source system gone down. A change made to a column name. The reality in data is that pipelines will always break and source systems will always go down.
But imagine the same root causes having a different end result: trust gets built.
Trust doesn’t break because something goes wrong. Trust breaks because consumers aren’t proactively made aware of something going wrong, and don’t have visibility into why it happened and if it will happen again.
In the past 2 years, innovation in the modern data stack has finally brought us to the point where the building blocks that we need to holistically bridge the data trust gap are in place — data testing has become more mainstream, data observability has matured, data pipeline & ingestion tools are opening up success and failure metadata, and generative AI is bridging the gap between business language and technical tooling.
It is now time for us to cross the final frontier — and build the right level of transparency between data producers and data consumers. And use these moments to build, not break, trust.
Interested to know more about how the top tools in the modern data stack are coming together to bridge the data trust gap? Join Atlan Activate this November to see the future of data trust in action.