
Ontologies, Context Graphs, and Semantic Layers: What AI Actually Needs in 2026
We've been working on semantic representation for decades—knowledge graphs, ontologies, semantic layers. Jessica Talisman untangles what they actually are and what AI needs from them.

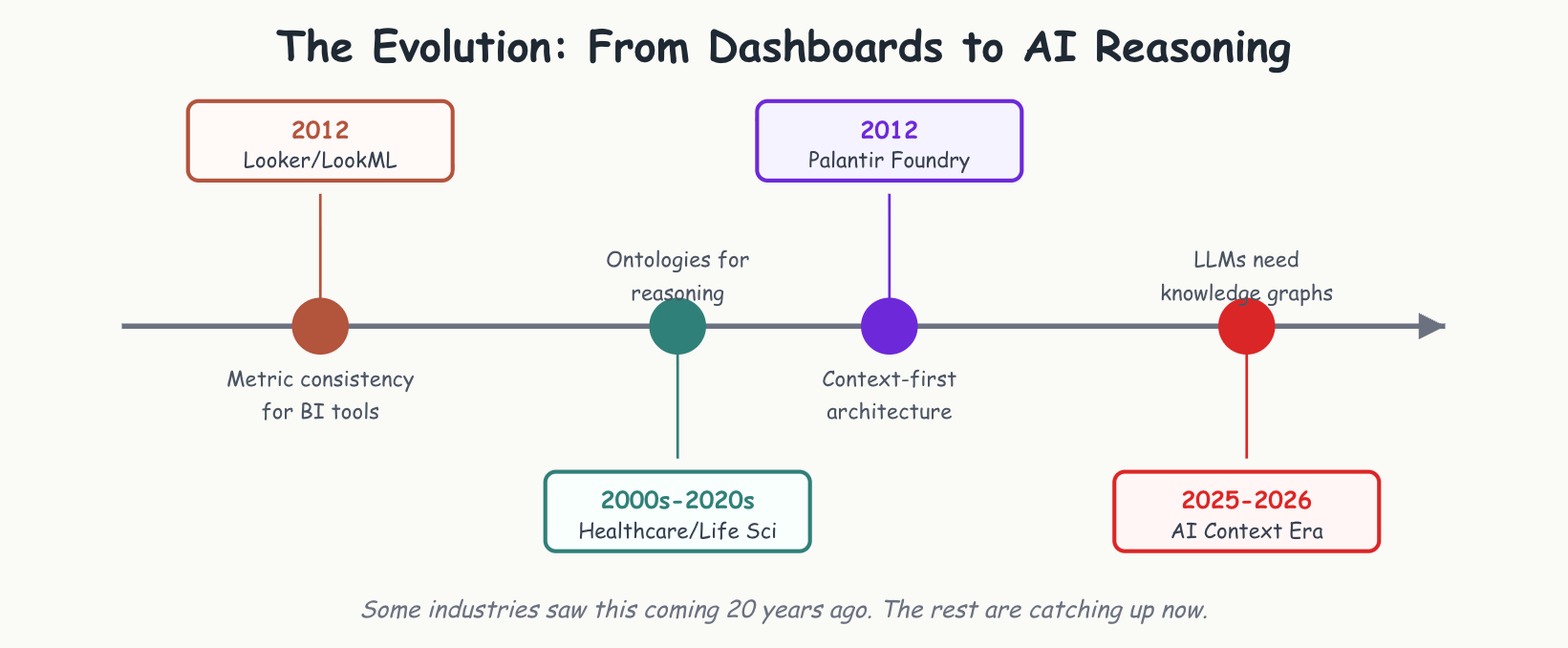
In 2012, Looker launched with LookML and a vision: define your metrics once, and business users could self-serve without SQL. Around the same time, life sciences, healthcare, and research organizations were building formal ontologies and knowledge graphs to model their data and their domains.
Both approaches promised to make data meaningful. A decade later, one powers dashboards. The other powers drug discovery that identifies cancer treatments, clinical decision support that prevents fatal drug interactions, and AI reasoning systems that intelligence agencies trust with life-or-death decisions.
One gave us prettier reports. The other gave us machines that can actually reason about meaning. Did we fundamentally misunderstand the problem we were trying to solve? AI is about to force a reckoning.
What we thought Semantic Layers would solve
The semantic layer emerged from a genuine data crisis. By the late 2000s, every organization with more than one database faced the same nightmare: different teams calculating “revenue” differently, analysts spending 80% of their time on data hygiene and preparation, and executives who couldn’t trust the numbers in their dashboards because they changed depending on who built them.
The promise was elegant: define your metrics once, govern them centrally, and let business users self-serve without writing SQL. Lloyd Tabb, Looker’s co-founder, described LookML as “the sequel to SQL,” a language that would let data teams create a semantic abstraction layer on top of raw databases, making data “easily accessible and understandable for non-technical users.”
And for what it was designed to do, it worked. Organizations using semantic layers did achieve more consistent metric definitions. Data teams did standardize their own work. The semantic layer delivered exactly what it promised.
But the idea that data problems had been solved was assumed, not conclusively realized.
We assumed that the core problem was calculation. That if we could just standardize how metrics were computed, meaning would follow. We assumed that the path from raw data to business understanding was a mathematical one.
But meaning isn’t the same as measurement. Knowing that revenue is calculated as SUM(order_total) WHERE order_status = ‘completed’ doesn’t tell you why revenue dropped in Q3, which customers are at risk, or what you should do about it.
Semantic layers modeled metrics and failed to represent an organization’s reality.
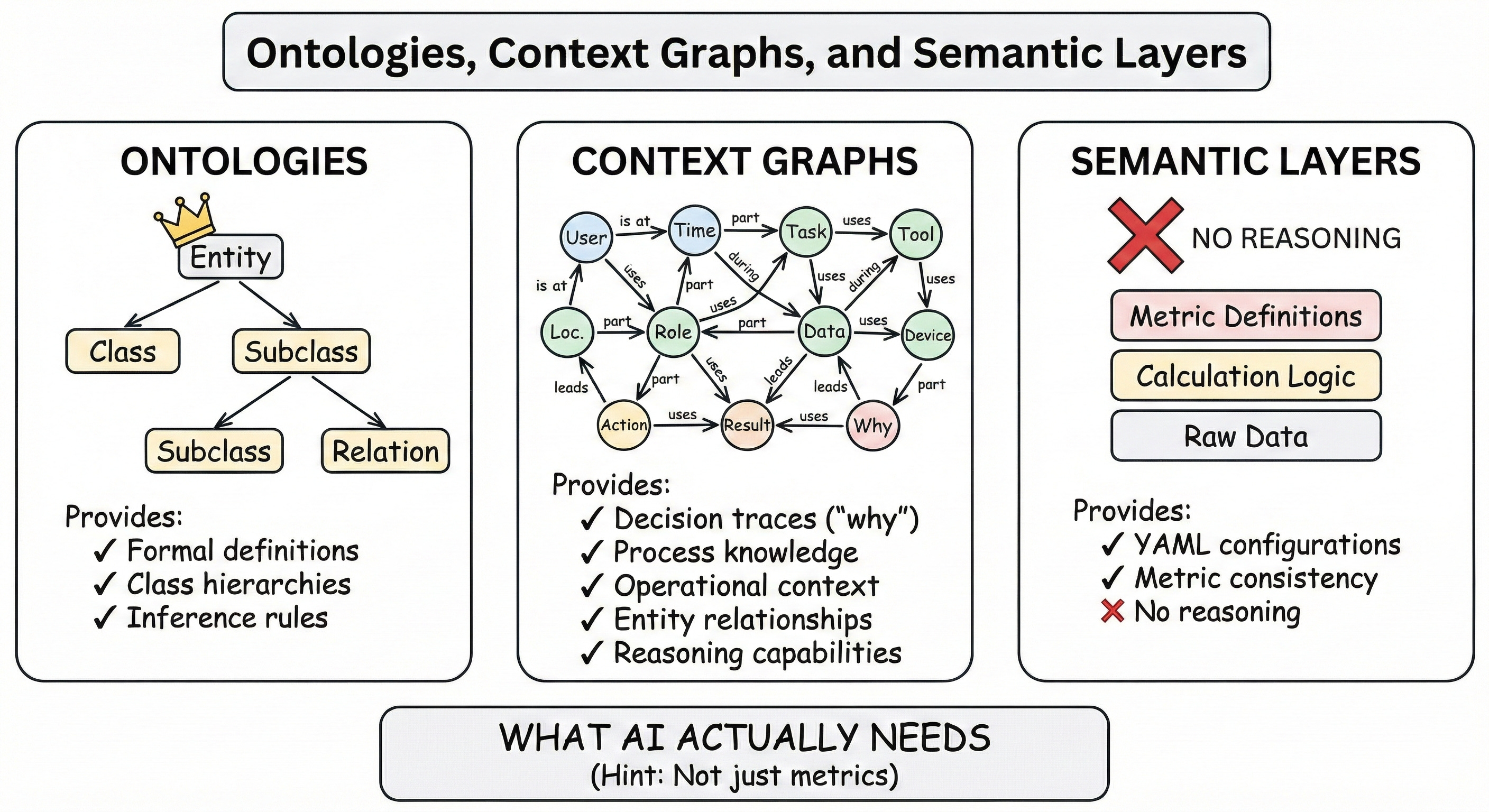
What Ontologies actually are
While the BI industry was perfecting metric consistency, other fields were solving a fundamentally different problem. Life sciences organizations needed to integrate research across thousands of studies using different vocabularies. Healthcare systems needed clinical decision support that understood patient data in addition to medical knowledge The Semantic Web community was building standards for machines to understand meaning, beyond processing syntax.
They were building ontologies (formal, explicit specifications of shared conceptualizations) to resolve system conflicts and manage ambiguity by modeling meaning.
Ontologies are structured representations of domain knowledge using standards like OWL (Web Ontology Language), SKOS (Simple Knowledge Organization System), and RDF (Resource Description Framework). They define classes of things, properties those things can have, attributes (descriptive decorations for ontology member elements), and relationships between them, all in machine-readable formats that support logical inference.
A great example of a medical ontology is the Gene Ontology, which has been foundational for bioinformatics for over two decades. It doesn’t only define metrics about genes – it models what genes are, what biological processes they participate in, what molecular functions they perform, and what cellular components they’re part of. The end result? A researcher queries the Gene Ontology to reliably discover things like “what is the count of genes in this pathway?” or to understand how these biological concepts relate to each other.
Another well-exercised example is SNOMED CT in healthcare, a comprehensive clinical terminology and companion ontology with over 350,000 concepts and millions of relationships. It enables systems to understand that “myocardial infarction” and “heart attack” refer to the same thing, that it’s a type of “ischemic heart disease,” and that it has specific relationships to symptoms, treatments, and anatomical structures.
When we look towards defining meaning with ontologies, we are ultimately talking about knowledge representation. Beyond metrics, ontologies seek to organize and manage knowledge, in order to support accurate capture and representation of, among other things, data.
You may be thinking, why do the differences between the semantic layer matter? Well, the structures and objectives of each are fundamentally distinct.
A semantic layer tells you things like what your revenue is or how many times a web page was visited more reliably, by normalizing text labels in natural language
An ontology can represent that a customer is defined as a class with specific attributes and properties. That customer placed an order and the items ordered are related to other products through specific direct and indirect relationships in a particular, defined market. The market is defined and represented as having specific characteristics. And because ontologies support inference, systems are able to extrapolate and derive new knowledge from explicit relationships.
The semantic layer architecture reflects a very different theory of knowledge. Semantic layers are built for analysis, helping humans consume data through BI tools, using natural language. Ontologies are built for reasoning, helping systems and AI understand domains well enough to disambiguate data, discover context, make inferences, and support decisions.
The difference isn’t just technical sophistication. Semantic layers and ontologies represent fundamentally different theories about what data systems are for. One optimizes for measurement. The other optimizes for meaning. We’ll return to this distinction, but first: while we were building one, someone else was betting on the other.
What Palantir saw that we didn’t
While the BI industry was perfecting LookML in 2012, Palantir was scaling Foundry across intelligence agencies and enterprises with a different bet—ontologies over semantic layers.
Palantir was building for operational decision making in contexts where understanding entity relationships and causal chains was mission-critical. Intelligence analysis. Supply chain orchestration. Financial crime detection.
The architecture was context-first, not metrics-first. In 2012, this looked like over-engineering for problems most businesses didn’t have. In 2026, as AI exposes the limits of YAML-based metric definitions, it looks prescient.
Were they right all along? Or did they solve a different problem than most organizations actually needed?
The answer may lie in understanding what Palantir was actually building, not just ontologies, but operational context graphs.
What Context Graphs actually capture
Even though Palantir’s ontology is closed and tool dependent, one could argue that what they have built is a context graph that is proprietary and specific to Palantir tools and environments.
When a VP approves a discount exceeding policy limits, traditional systems record the decision but not the reasoning. When a maintenance technician modifies a procedure, the justification exists in their head, not in the system. Context graphs aim to create living records of this decision reasoning, answering “Why was X allowed to happen?” rather than just “What happened?”
Understanding the difference is important. Knowledge graphs tell you that a customer placed an order. Context graphs are also knowledge graphs. A context graph can tell you why that order was approved despite violating standard terms, what precedent existed for similar exceptions, who had authority to approve it, and what conditions justified the deviation.
Building such systems requires formal methodology for representing process knowledge. The Procedural Knowledge Ontology (PKO), developed by researchers at Cefriel with industrial partners including Siemens and BOSCH, provides the semantic architecture that context graphs need. PKO distinguishes between procedures (abstract specifications of how to accomplish something) and executions (concrete instances of those procedures being performed). A safety lockout procedure specifies general steps. A lockout execution represents a specific technician performing that procedure on a specific date with specific observations and outcomes.
The ontology organizes knowledge across six conceptual areas: procedure specifications, granular action steps, change tracking (who modified what and when), execution histories, agent roles and authority, and supporting documentation. Together, these create the audit trails and precedent records that AI agents need to handle ambiguous, judgment-laden situations.
Organizations like Siemens have proven this works in practice. By modeling microgrid device operations as procedures with specified states and transitions, they transformed previously undocumented controller logic into explicit, queryable knowledge. Electric vehicle owners can now understand why their charging patterns behave as they do—not just that charging was slow, but why (low photovoltaic production, high grid demand, battery capacity limits) and when optimal conditions typically occur. Operators can analyze execution patterns across devices and troubleshoot anomalies with full contextual visibility.
But here’s the critical challenge: this is fundamentally a knowledge management problem. Context graphs require systematic elicitation of tacit knowledge—observing work practices, interviewing experts, extracting undocumented reasoning, and encoding it in formal representations. Without this investment in knowledge engineering, decision traces remain trapped in Slack threads, email chains, and institutional memory that no system can index or query.
The organizations that solve this—that treat context capture as a core competency rather than a side project—will possess what may be the decisive competitive advantage in the AI era: the ability to explain not just what happened, but why it was allowed to happen.
Suggested reads


The YAML problem
Let’s be direct about what we got wrong: We tried to encode business meaning in YAML files.
Look at how the dbt Semantic Layer works: MetricFlow “uses information from semantic model and metric YAML configurations to construct and run SQL in a user’s data platform.” The entire edifice of modern semantic layers rests on the assumption that YAML declarations can capture business semantics.
yaml
semantic_models:
- name: orders
defaults:
agg_time_dimension: order_date
entities:
- name: order_id
type: primary
measures:
- name: order_total
agg: sumThis is a mighty fine solution for metric governance. But it certainly is not a model of the business. YAML configs are models of calculations, and capture SQL table and column representations. They are database entities, plain and simple – absent of relationships, natural language, definitions, and rich context. The relationships are join paths, and missing semantic relationships or business processes.
Compare this to how an ontology would represent the same domain:
turtle
EXPLICIT:
:Alice :placedOrder :Order001 .
:Order001 :hasItem :Item001 .
:Item001 :itemProduct :Laptop .
:Alice :customerLifetimeValue “1250.00”^^xsd:decimal .
INFERRED (what you get automatically):
:Alice a :HighValueCustomer . # Reasoner infers this
:Alice :purchased :Laptop . # Property chain inference
:Order001 :orderedBy :Alice . # Inverse property
:Laptop :frequentlyBoughtWith :Mouse . # Symmetric property
:Alice :knowsCustomer :Carol . # Transitive reasoningThe ontological representation captures meaning that the YAML cannot. An ontology can describe that an order is a type of business transaction, that it's placed by a customer, who is a type of person, that has orders that are different from quotes and invoices. Ontologies extend beyond labels and verification that those labels exist. Ontologies contain logical semantic assertions that support inference.
While we thought structured metadata would be enough, the entire technology industry is learning (albeit slowly) that we assumed data teams could model business logic. We were wrong on all three counts.
While the metadata was indeed structural, it certainly was not semantic, in spite of the name ‘semantic layer.’ The logic was stuck in syntax and compute, not representational, descriptive, or context-rich. To model ontologies, domain expertise and formal knowledge engineering skills were required, skills that most data teams simply don’t have. Ontology construction required understanding how to represent knowledge, not just how to calculate metrics.
This in no way is a criticism of data teams. We have to face the harsh reality that metric definition and ontology engineering are fundamentally different disciplines. Let’s not fool ourselves in thinking that ontologies and semantic layers are remotely similar in objectives or end results.
Just as you wouldn’t ask a financial analyst to build clinical terminology, you certainly wouldn’t expect a data engineer to model your domain’s knowledge structure. Or would you?
Why AI changes everything
In October 2025, dbt Labs made a remarkable announcement at Coalesce: they were open-sourcing MetricFlow under the Apache 2.0 license. The stated reason? “As it turns out, the semantic layer is the critical component to build a bridge between AI and structured data.”
They’re right about the problem, but the solution may require more than their current architecture can provide.
The industry has learned that LLMs need context and meaning, not dashboards. LLMs need to understand what things are, how they relate, and what actions are possible. This is what ontologies and knowledge graphs provide, not a capability of semantic layers. A semantic layer is for lookup, an ontology is for context and reasoning.
The Context requirement
We have established that AI agents require operational context. As Anthropic’s engineering team recently wrote, “context engineering is the discipline of designing a system that provides the right information and tools, in the right format, to give an LLM everything it needs to accomplish a task.”
Context, in this framing, includes “prompts, memories, few-shot examples, tool descriptions,” the full semantic environment in which the model operates. Not something the semantic layer can provide wholesale.
Knowledge graphs and ontologies are purpose-built for this kind of context provision. They represent not just data, but the concepts, relationships, and constraints that give data meaning. An LLM can query a knowledge graph and gain access to structured domain knowledge that goes far beyond the constraints of semantic layers, and what metric definitions provide.
This is why healthcare AI systems increasingly rely on clinical ontologies, why drug discovery platforms are built on biomedical knowledge graphs, and why enterprise AI deployments are starting to incorporate semantic technologies. The domains that have invested in formal knowledge representation are ahead of the context game, able to show where AI reasoning actually works at scale.
AI systems have demonstrated that we must build dynamic and descriptive knowledge infrastructures to support human and machine consumption. As AI works in the realms of natural language, SQL-ized labels and syntactic representations of data won’t cut the very human requirement in how we represent data.
While metric definitions are ultimately optimized for human consumption through visualization tools and dashboards, the underlying semantics are, in fact, missing. Knowledge graphs and ontologies optimize for machine and human readability while also built to support inference and reasoning.
The real architectural difference
Let’s examine what semantic layer and ontology architectures provide:
Semantic layers are designed for humans to consume through BI tools. They offer metric definitions and calculations, dimensional models for analysis, SQL abstraction so business users don’t need technical skills, and consistency across reporting tools. They answer metrics-based questions and are constrained to their “What is X?”
Ontologies and knowledge graphs are designed for system and domain understanding. They provide formal concept definitions and taxonomies, explicit relationship types with semantic meaning, support for logical inference and reasoning, interoperability through standard formats (RDF, OWL, SKOS), and integration of domain expertise into machine-readable form. They provide context without SQL and table constraints.
The architectural difference reflects different theories about what data systems are for.
Semantic layers emerged from the BI industry’s focus on reporting and metrics. The core problem was consistent measurement across tools and teams. The solution was centralized metric governance.
Ontologies are a form of neuro-symbolic AI and emerged from knowledge management, library science, and artificial intelligence research, fields where the core problem was representing and reasoning about domain knowledge. The solution was formal knowledge representation with standards that enable interoperability and inference.
While both approaches work, they serve different purposes and work to achieve different things.
The hard questions for 2026
The emergence of AI as a primary consumer of data architecture forces some uncomfortable questions onto the industry.
Is there a middle ground? Is it possible to build “context-aware semantic layers” that maintain metric governance while adding the semantic richness ontologies provide? The Open Semantic Interchange initiative, which dbt Labs joined alongside Snowflake and Salesforce in 2025, hints at this direction.
But the gap between metric definitions and formal ontologies may be too wide to bridge out of the gate, since YAML configurations and ontology formats represent different theories, operational requirements, development resources, and meaning.
Can semantic layers evolve into knowledge graphs? The data infrastructure already exists. The metric definitions already exist. Can organizations layer ontological structure on top of or connecting to their semantic layers?
Some companies and research organizations are trying. But adding classes, properties, and inference rules to a system designed for SQL generation may require such fundamental architectural changes that you’d essentially be building a knowledge graph from scratch anyway.
Do we need a new category entirely? Perhaps neither “semantic layer” nor “ontology” captures what AI-native data architecture actually requires. The term “context engineering“ has gained traction. Shopify CEO Tobi Lütke described it as “the art of providing all the context for the task to be plausibly solvable by the LLM.”
But context engineering is a practice, not a platform. What would a “ContextOS” actually look like? Probably something that combines metric governance with knowledge representation – but that’s easier to name than to build.
Where does dbt’s semantic layer fit in this future? The open-sourcing of MetricFlow and the OSI initiative suggest dbt Labs sees AI as the primary use case going forward. Their documentation now describes the semantic layer as enabling “AI agents to leverage trusted metric definitions for governed conversational analytics.”
But is governed conversational analytics enough? Or do agents need the kind of domain knowledge and contextual understanding that only formal ontologies and knowledge graphs provide?
Is the metrics-first paradigm dead? This may be the hardest question. The entire modern data stack was built on the assumption that measurement is the foundation of understanding. But AI systems reason differently than human analysts. They don’t need metrics presented in charts; they need concepts, relationships, and inference capabilities.
Does this mean the metrics-first paradigm is obsolete, or does it mean metrics become one input to a richer knowledge architecture?
But haven’t we heard this before?
Here’s the uncomfortable question: Are ontologies just another hype cycle?
The Semantic Web was supposed to revolutionize the internet 20 years ago. Knowledge graphs were going to replace databases. Yet most organizations that try to build ontologies either fail or abandon them.
The skeptical case: Ontology construction requires rare skills (knowledge engineering, formal logic), years of investment, and organizational commitment that few companies sustain. Maybe semantic layers aren’t the wrong architecture. Maybe we’re looking for technical solutions to organizational problems.
The counter-argument: This time is different because AI changes the stakes. Healthcare and life sciences invested in ontologies not because they were trendy, but because their work required formal knowledge representation. Gene Ontology has been foundational for bioinformatics for 20+ years because the alternative simply doesn’t work.
Now AI makes knowledge reasoning business-critical for everyone. The question isn’t whether ontologies work (they do, in domains that invest in them). The question is whether your organization will actually build one.
What this means, practically
If you’re building an AI analyst, you need knowledge representation, not just metrics. Your AI doesn’t consume dashboards, it consumes semantic representations. If that representation only includes metric definitions without concept hierarchies, relationship types, or domain knowledge, your AI can only answer calculation questions, not reasoning or inference questions.
If you’re evaluating semantic layers, ask: “Is this for humans or for AI?” The answer determines whether metric governance is sufficient or whether you need richer knowledge modeling. Most organizations will need both, but building for humans and building for AI may require different architectures.
If you’re considering knowledge graphs or ontologies, prepare for a different kind of investment. Unlike semantic layers, which data teams can define relatively quickly, ontologies require domain expertise, knowledge management, & engineering skills, and often years of iterative refinement. The organizations that have succeeded (in life sciences, healthcare, finance) have treated knowledge representation as a core competency, rather than a product or project.
The winners will be those who solve for meaning, not simply for calculation. Consistent metrics are table stakes. The competitive advantage goes to organizations whose data architecture can support AI reasoning about concepts, relationships, and domain knowledge, moving beyond aggregation and filtering.
Where do we go from here?
Here’s what I think is actually true: the semantic layer vs. ontology framing may itself be too narrow.
Semantic layers were designed for a world where humans consumed data through dashboards. Ontologies were designed for domains where reasoning about knowledge (not just querying data) was the core requirement. Both make sense, depending on the tasks at hand.
But AI changes the context.
The question isn’t whether to adopt semantic layers or ontologies. It’s whether your data architecture can provide AI systems with what they need to reason about your domain. For some use cases (metric lookup, calculation consistency, basic analytics), semantic layers remain sufficient. For others (complex reasoning, inference, elicitation of meaning and domain-specific AI), they won’t be.
The more important question is: what do we do now?
Because whether we call it semantic layers 2.0, knowledge graphs, context engineering, context graphs, or something entirely new, the era of metrics-based thinking is coming to a close. AI systems need to understand what your domain is: the concepts, the relationships, the constraints, the inference rules.
It’s a knowledge architecture problem.
And knowledge architecture is an entirely different discipline, requiring different skills, than defining metric definitions. It’s closer to what librarians, taxonomists, and knowledge engineers have done for decades, and is a drastically different workflow than what data teams typically do today. It requires understanding how to formally represent domain knowledge, skills that fields like library science, information architecture, and semantic web research have been developing for years.
The organizations that roll up their sleeves and build AI systems that can actually reason about their domains will prevail. The ones that don’t rise to the challenge will have very consistent calculations, but not the knowledge infrastructure their AI can actually use.
It’s a knowledge architecture problem. And knowledge architecture is an entirely different discipline than defining metrics. It’s closer to what librarians, taxonomists, and knowledge engineers have done for decades—skills that fields like library science, information architecture, and semantic web research have been developing for years.
The question isn’t whether you’ll eventually need this. It’s whether you’ll start building now, or wait until your competitors have a three-year head start.
Healthcare and life sciences made their bet 20 years ago. Palantir made their closed ontology-ish system in 2012. What’s yours?
We're exploring these architectural choices and their strategic implications at The Great Data Debate with thought leaders who are shaping the space from some of the world’s leading organizations. Join Jaya Gupta (Foundation Capital), Karthik Ravindran (Microsoft), Bob Muglia (Snowflake), and Tony Gentilcore (Glean) as they debate the paths forward: Can semantic layers evolve? Do enterprises need ontologies? And who's positioned to capture the trillion-dollar context graph opportunity?
I’d love to hear what you think. Share your thoughts in the comments!
References
First Round Review. “The Inside Story of How This Startup Turned a 216-Word Pitch Email into a $2.6 Billion Acquisition.” October 2024.
dbt Labs. “Announcing open source MetricFlow: Governed metrics to power trustworthy AI and agents.” October 14, 2025.
dbt Labs. “dbt Labs Affirms Commitment to Open Semantic Interchange by Open Sourcing MetricFlow.” Press Release. October 14, 2025.
Anthropic. “Effective context engineering for AI agents.” Anthropic Engineering Blog.
LangChain. “Context Engineering for Agents.” October 19, 2025.
Google Developers Blog. “Architecting efficient context-aware multi-agent framework for production.” December 4, 2025.
Gene Ontology Consortium. http://geneontology.org/
SNOMED International. https://www.snomed.org/
W3C. “OWL 2 Web Ontology Language.” https://www.w3.org/TR/owl2-overview/
typedef.ai. “Semantic Layer 2025: MetricFlow vs Snowflake vs Databricks.” November 2025.
About Author

The Insight Index: Your Weekly Data & AI Digest
Top resources and recommended reads, carefully curated for you.
Context Graphs, Data Traces & Transcripts — Kurt Cagle
Ontologies - Some Perspectives — William Inmon & Jessica Talisman
Semantically Speaking: What Context Graphs Made Impossible to Ignore — J Bittner & Colbie Reed
How Context Graphs Turn Agent Traces Into Durable Business Assets — Aparna Dhinakaran
Context Graphs: The Elegant Idea Everyone’s Talking About — Dharmesh Shah
How to build a context graph — Animesh Koratana
Decision Traces Are Only as Good as the Context That Fed Them — Shirshanka Das
Context Graphs: AI’s Next Big Idea — The AI Daily Brief
This list is intended to help you explore diverse perspectives and does not represent the views of the author or the community as a whole.
That’s all for this edition. Stay curious, keep exploring, and see you all in the next one!
About Metadata Weekly
Metadata Weekly isn’t just a newsletter. It’s shared community space where practitioners, builders, and thinkers come together to share stories, lessons, and ideas about what truly matters in the world of data and AI: trust, governance, context, discovery, and the human side of doing meaningful work.
Our goal is simple, to create a space that cuts through the noise and celebrates the people behind the amazing things that are happening in the data & AI domain.
Whether you’re solving messy problems, experimenting with AI, or figuring out how to make data more human, Metadata Weekly is your place to learn, reflect, and connect.
Got something on your mind? We’d love to hear from you. Hit Reply!
 | A guest post by
|